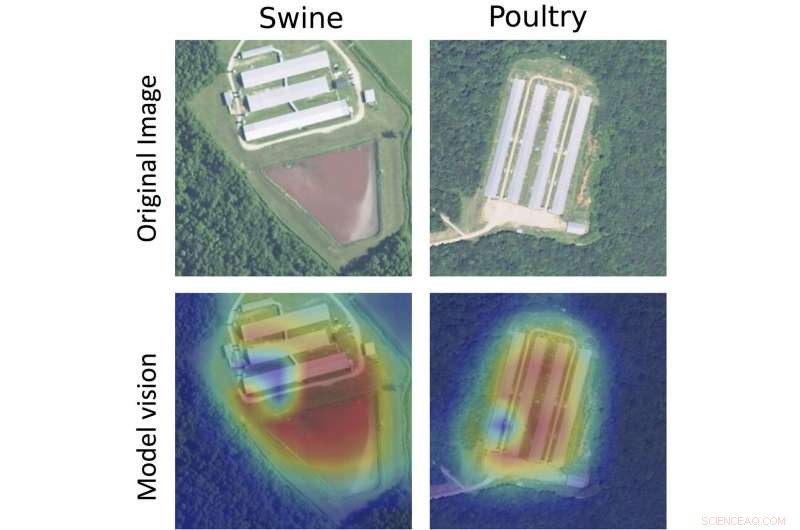
Provanläggningar för svin (vänster) och fjäderfä (höger), med originalbilden (överst) och en värmekarta över hur de algoritmiska modellerna bearbetade bilden (nederst). De röda områdena visar var modellen upptäckte sannolikheten för anläggningsplatser. Kredit:National Agriculture Imagery Program / U.S. Department of Agriculture
Hur man lokaliserar potentiellt förorenande djurgårdar har länge varit ett problem för miljötillsynsmyndigheter. Nu, Stanford-forskare visar hur en kartläsningsalgoritm kan hjälpa tillsynsmyndigheter att identifiera anläggningar mer effektivt än någonsin tidigare.
Juridikprofessor Daniel Ho, tillsammans med Ph.D. student Cassandra Handan-Nader, har hittat ut ett sätt för maskininlärning – lära en dator hur man identifierar och analyserar mönster i data – för att effektivt lokalisera industriella djurverksamheter och hjälpa tillsynsmyndigheter att fastställa varje anläggnings miljörisk. Forskarnas resultat kommer att publiceras den 8 april Naturens hållbarhet .
"Vårt arbete visar hur en statlig myndighet kan utnyttja snabba framsteg inom datorseende för att skydda rent vatten mer effektivt, sa Ho, William Benjamin Scott och Luna M. Scott professor i juridik, och en senior fellow vid Stanford Institute for Economic Policy Research.
Ett grundläggande problem, med komplexa konsekvenser
Enligt Environmental Protection Agency (EPA), jordbruket är den ledande bidragsgivaren av föroreningar till landets vattenförsörjning, med betydande föroreningar som tros härröra från storskaliga, koncentrerad djurfodring, även känd som CAFOs.
Men miljöövervakningsinsatser har hindrats av ett grundläggande problem:Tillsynsmyndigheter har inget systematiskt sätt att avgöra var CAFOs finns, sa Ho. United States Government Accountability Office rapporterar att ingen federal myndighet har tillförlitlig information om numret, storlek och lokalisering av storskalig jordbruksverksamhet.
Även om Clean Water Act kräver vissa federala tillstånd, det gäller endast verksamheter som faktiskt släpper ut föroreningar i amerikanska vattendrag – inte anläggningar som potentiellt kan orsaka förorening – avsiktligt eller inte, sa Ho.
Utan någon bestämd lista att vända sig till, ansträngningar för att övervaka potentiellt förorenande anläggningar är svåra och, i vissa fall, omöjlig.
"Det här informationsunderskottet kväver upprätthållandet av miljölagarna i USA, " sa Ho.
Vissa miljö- och allmänintressen har försökt identifiera anläggningar själva genom att skanna terräng manuellt eller titta på flygfoton, men de har tyckt att det är en otroligt tidskrävande uppgift. Det tog en miljögrupp över tre år att titta på bilder från bara en stat. Att övervaka ansträngningar som dessa kunde aldrig skalas eller göras i realtid, sa Ho.
Använder big data för att fylla i luckorna
Ho och Handan-Nader, sedan forskare vid Stanford Law School och doktorerar nu i statsvetenskap, riktade sin uppmärksamhet mot en typ av artificiell intelligens som kallas djupinlärning. En delmängd av maskininlärning, djupinlärningsalgoritmer har revolutionerat förmågan att upptäcka komplexa objekt i bilder.
Med hjälp av flera verktyg med öppen källkod och ett team av studenter inom ekonomi och datavetenskap för att hjälpa till med dataanalys, Ho och Handan-Nader kunde omskola en befintlig bildigenkänningsmodell för att känna igen storskaliga djuranläggningar genom att använda information som samlats in av två ideella grupper och allmänt tillgängliga satellitbilder från USDA:s National Agricultural Imagery Program (NAIP). Forskarna fokuserade på att försöka identifiera fjäderfäanläggningar i North Carolina eftersom de flesta inte krävs för att få tillstånd, sa Ho.
Modellen, redan kunniga i att skanna bilder baserat på en enorm samling digitala bilder, skolades om för att fånga upp liknande ledtrådar som miljöorganisationerna hade övervakat manuellt. Till exempel, svinfarmer kunde identifieras genom kompakta rektangulära ladugårdar som gränsar till stora flytgödselbrunnar, och fjäderfä vid långa rektangulära ladugårdar och torrgödselförvaring. Genom att inrikta sig på dessa framträdande egenskaper, modellen kunde också ge storleksuppskattningar för anläggningarna.
Forskarna fann att deras algoritm kunde identifiera 15 procent fler fjäderfäfarmar än vad som ursprungligen hittades genom manuella ansträngningar. Och eftersom deras tillvägagångssätt kunde skala över år av NAIP-bilder, deras algoritm kunde exakt uppskatta tillväxten i närheten av en nyligen byggd foderfabrik.
"Modellen upptäckte 93 procent av alla fjäderfä CAFOs i området, och var 97 procent exakt när det gällde att avgöra vilka som dök upp efter att foderkvarnen öppnade, Handan-Nader och Ho skriver i tidningen.
Komplementär, tvärvetenskapligt förhållningssätt
Ho och Handan-Nader hoppas att maskininlärning kan komplettera miljöbyråernas och intressegruppernas mänskliga övervakningsinsatser.
"Nu kan alla typer av forskare med programmeringsförmåga utnyttja dessa open source-verktyg för nya applikationer, sade Handan-Nader, en medförfattare på tidningen. "Du kan stå på jättarnas axlar och utveckla vad experter inom den här typen av maskininlärningsteknik har gjort."
Att använda maskininlärning för utantillbörliga uppgifter kan befria människor att göra mer komplexa, t.ex. att fastställa möjliga miljöfaror med en anläggning, sa Handan-Nader. Forskarna uppskattade att deras algoritm kunde fånga 95 procent av befintliga storskaliga anläggningar med mindre än 10 procent av de resurser som krävs för en manuell folkräkning.
Ho och Handan-Nader hoppas att så småningom, Framsteg inom flygbilder kommer att göra det möjligt för en datormodell att upptäcka faktiska utsläpp i vattendrag.
"Alltmer, komplexa sociala problem kan inte lösas från enbart en snäv disciplin, och förmågan att utnyttja innovation över campus kan hjälpa till att ta itu med kärnproblemen i lag och offentlig politik, " sa Ho.