Datadriven artificiell intelligens, såsom djupinlärning och förstärkningsinlärning, har kraftfulla dataanalysfunktioner. Dessa tekniker möjliggör statistisk och probabilistisk analys av data, vilket underlättar kartläggningen av sambanden mellan indata och utdata utan att förlita sig på förutbestämda fysiska antaganden.
Centralt i processen att träna datadrivna modeller är utnyttjandet av en förlustfunktion, som beräknar skillnaden mellan modellens output och de önskade målresultaten (etiketter). Optimeraren justerar sedan modellens parametrar baserat på förlustfunktionen för att minimera skillnaden mellan utdata och etiketter.
Samtidigt involverar geofysisk loggning en mängd domänkunskap, matematiska modeller och fysiska modeller. Att enbart beroende av datadrivna modeller kan ibland ge resultat som motsäger etablerad kunskap. Dessutom kan träningsdata med ojämn fördelning och subjektiva etiketter också påverka prestandan hos datadrivna modeller.
En nyligen publicerad studie publicerad i Artificial Intelligence in Geoscience rapporterade implementeringen av begränsningar för utbildning av datadrivna maskininlärningsmodeller som använder loggningssvarsfunktioner i brunnsloggning av reservoarparameterförutsägelser.
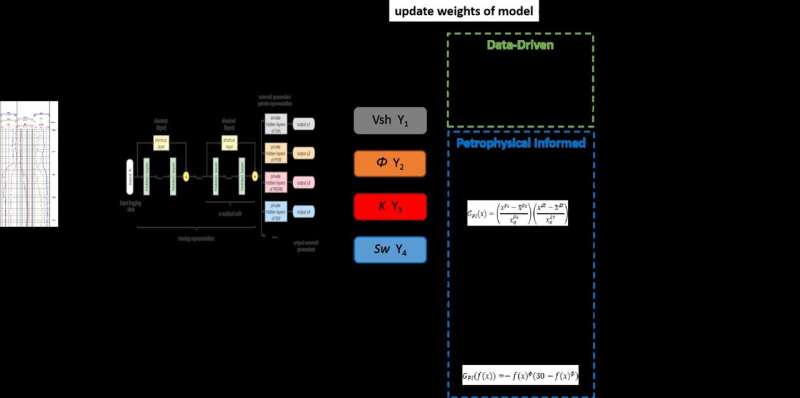
"Vår modell, kallad Petrophysics Informed Neural Network (PINN), integrerar petrofysiska begränsningar i förlustfunktionen för att vägleda träning", säger studiens första författare, Rongbo Shao, en Ph.D. kandidat från China University of Petroleum-Beijing. "Under modellträning, om modellutdata skiljer sig från petrofysikkunskap, straffas förlustfunktionen av petrofysiska begränsningar. Detta för utdata närmare det teoretiska värdet och minskar effekten av märkningsfel på modellträning."
Dessutom hjälper detta tillvägagångssätt att urskilja de korrekta sambanden från träningsdata, särskilt när det handlar om små urvalsstorlekar.
"Vi introducerar tillåtna felvikter och petrofysiska begränsningsvikter för att göra inflytandet av mekanismmodeller i maskininlärningsmodellen mer flexibel", utarbetar Shao. "Vi utvärderade PINN-modellens förmåga att förutsäga reservoarparametrar med hjälp av uppmätta data."
Shao och hans kollegor fann att modellen har förbättrat noggrannhet och robusthet jämfört med rena datadrivna modeller. Icke desto mindre noterade forskarna att val av petrofysiska begränsningsvikter och tillåtna fel förblir subjektivt, vilket kräver ytterligare utforskning.
Motsvarande författare Prof Lizhi Xiao från China University of Petroleum understryker betydelsen av denna forskning, "Att integrera datadrivna AI-modeller med kunskapsdrivna mekanismmodeller är ett lovande forskningsområde. Framgången för PINN-modellen inom brunnsloggning är ett viktigt steg framåt. för geovetenskap i denna riktning."
Xiao betonar behovet av fortsatt förfining, "Valet av petrofysiska begränsningsvikter och tillåtna fel, såväl som domänkunskapens anpassningsförmåga till olika geologiska strata, utgör pågående utmaningar. Dessutom är kvaliteten på datamängder avgörande för tillämpningen av AI i Geofysisk loggning Omfattande, allmänt tillgängliga brunnsloggningsdatauppsättningar med hög kvalitet och kvantitet behövs."
Mer information: Rongbo Shao et al, Reservoarutvärdering med petrofysikinformerad maskininlärning:En fallstudie, Artificial Intelligence in Geosciences (2024). DOI:10.1016/j.aiig.2024.100070
Tillhandahålls av KeAi Communications Co.