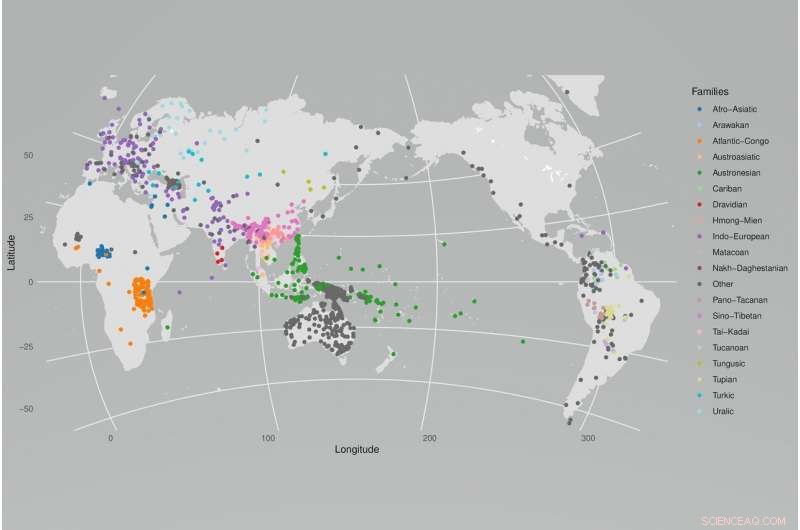
Global distribution av språk som ingår i CLICS3-utgåvan, identifieras av språkfamiljen. Kredit:S. J. Greenhill
Varje språk har fall där två eller flera begrepp uttrycks med samma ord, som det engelska ordet "fly, " som hänvisar till både flygandet och insekten. Genom att jämföra mönster i dessa fall, som lingvister kallar kolexifikationer, över språk, forskare kan få insikter i en lång rad frågor, inklusive mänsklig uppfattning, språkutveckling och språkkontakt. Den tredje delen av CLICS-databasen ökar avsevärt antalet språk, koncept, och datakällor tillgängliga i tidigare versioner, gör det möjligt för forskare att studera kolexifikationer i global skala i oöverträffad detalj och djup.
Med detaljerade datorstödda arbetsflöden, CLICS underlättar standardiseringen av språkliga datamängder och tillhandahåller lösningar på många av de ihållande utmaningarna inom språkforskning. "Medan dataaggregering i allmänhet baserades på ad-hoc-procedurer tidigare, våra nya arbetsflöden och riktlinjer för bästa praxis är ett viktigt steg för att garantera reproducerbarheten av språklig forskning, säger Tiago Tresoldi.
Effektiviteten av CLICS demonstreras i forskningsapplikationer
CLICS förmåga att tillhandahålla nya bevis för att ta itu med spjutspetsfrågor inom psykologi och kognition har redan illustrerats i en nyligen publicerad studie i Vetenskap , som koncentrerade sig på den världsomfattande kodningen av känslomässiga begrepp. Studien jämförde kolexifieringsnätverk av ord för känslomässiga begrepp från ett globalt urval av språk, och avslöjade att innebörden av känslor varierar mycket mellan språkfamiljer.
"I den här studien, CLICS användes för att studera skillnader i lexikal kodning av känslor på språk runt om i världen, men databasens potential är inte begränsad till känslokoncept. Många fler intressanta frågor kan tas upp i framtiden, säger Johann-Mattis List.
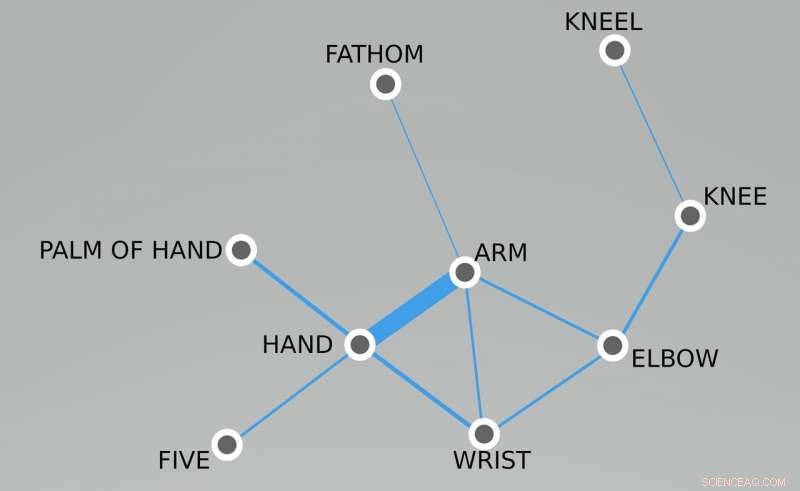
Kolexifieringsnätverket centrerat på begreppen "hand" och "arm". Kredit:J.-M. Lista, T. Tresoldi
Nya standarder och arbetsflöden möjliggör reproducerbar insamling av globala lexikaliska data
Att bygga vidare på de nya riktlinjerna för standardiserade dataformat inom tvärspråklig forskning, som först presenterades 2018, CLICS-teamet kunde öka mängden data från 300 språkvarianter och 1200 koncept i den ursprungliga databasen till 3156 språkvarianter och 2906 koncept i den nuvarande installationen. Den nya versionen garanterar också reproducerbarheten av dataaggregeringsprocessen, överensstämmer med bästa praxis för hantering av forskningsdata. "Tack vare de nya standarder och arbetsflöden vi utvecklat, vår data är inte bara RÄTTVIS (finnbar, tillgänglig, interoperabel, och reproducerbar), men processen att lyfta språkliga data från deras ursprungliga former till våra tvärspråkliga standarder är också mycket effektivare än tidigare, " säger Robert Forkel.
Effektiviteten av arbetsflödet som utvecklats för CLICS har testats och bekräftats i olika valideringsexperiment som involverar ett stort antal forskare och studenter. Två olika elevuppgifter genomfördes, vilket resulterar i skapandet av nya datamängder och en progressiv förbättring av befintliga data. Eleverna fick i uppdrag att arbeta igenom de olika stegen för att skapa datamängder som beskrivs i studien, t.ex. dataextraktion, datakartläggning (för att referera till kataloger), och identifiering av källor. "Att låta personer utanför kärnteamet använda och testa dina verktyg är viktigt och hjälper enormt med att finjustera alla processer, säger Christoph Rzymski.
Eftersom CLICS och dess arbetsflöde är tillgängligt för en bredare publik, Forskare kan inte bara bidra direkt till databasen i framtiden; de kan också dra nytta av det etablerade maskineriet och starta egna riktade insamlingar. "Antalet lingvister som aktivt använder våra standarder och arbetsflöden ökar ständigt. Vi hoppas att lanseringen av denna nya version av CLICS kommer att sprida dem ytterligare, säger Simon Greenhill.