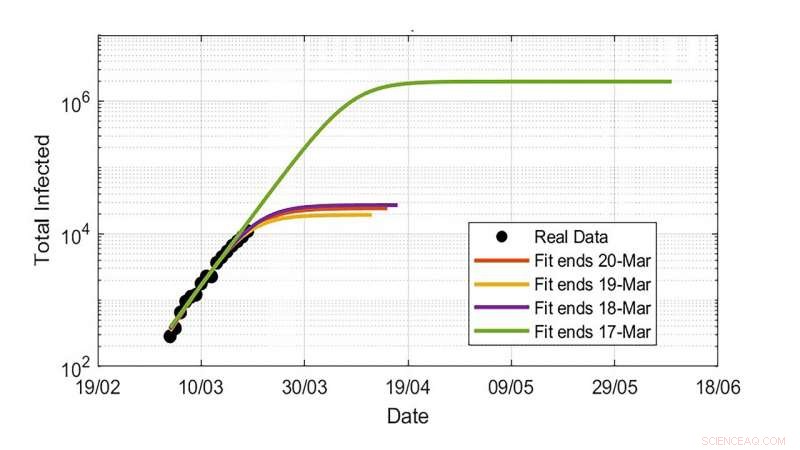
Uppskattningar av det totala antalet infektioner med COVID-19-infektioner inom Storbritannien. Extrapolationer visar enorma fluktuationer beroende på storleken på den sista tillgängliga datapunkten. Kredit:Davide Faranda
När det smittsamma viruset som orsakade COVID-19-sjukdomen började sin förödande spridning över hela världen, ett internationellt team av vetenskapsmän var oroade över bristen på enhetliga tillvägagångssätt från olika länders epidemiologer för att svara på det.
Tyskland, till exempel, inledde inte en fullständig lockdown, till skillnad från Frankrike och Storbritannien, och beslutet i USA av New York att gå in i en lockdown kom först efter att pandemin hade nått ett framskridet stadium. Datamodellering för att förutsäga antalet troliga infektioner varierade kraftigt efter region, från mycket stora till mycket små antal, och avslöjade en hög grad av osäkerhet.
Davide Faranda, en vetenskapsman vid det franska nationella centret för vetenskaplig forskning (CNRS), och kollegor i Storbritannien, Mexiko, Danmark, och Japan bestämde sig för att utforska ursprunget till dessa osäkerheter. Detta arbete är djupt personligt för Faranda, vars farfar dog av covid-19; Faranda har tillägnat honom arbetet.
I journalen Kaos , gruppen beskriver varför modellering och extrapolering av utvecklingen av covid-19-utbrott i nästan realtid är en enorm vetenskaplig utmaning som kräver en djup förståelse för de olinjäriteter som ligger bakom epidemiers dynamik.
Förutsäga beteendet hos ett komplext system, som epidemiers utveckling, kräver både en fysisk modell för dess utveckling och en datauppsättning av infektioner för att initiera modellen. För att skapa en modell, teamet använde data från Johns Hopkins Universitys Center for Systems Science and Engineering, som är tillgänglig online på https://systems.jhu.edu/research/public-health/ncov/ eller https://github.com/CSSEGISandData/COVID-19.
"Vår fysiska modell är baserad på att anta att den totala befolkningen kan delas in i fyra grupper:de som är mottagliga för att fånga viruset, de som har fått viruset men inte visar några symtom, de som är smittade och, till sist, de som tillfrisknat eller dog av viruset, sa Faranda.
För att avgöra hur människor flyttar från en grupp till en annan, det är nödvändigt att känna till infektionsfrekvensen, inkubationstid och återhämtningstid. Faktiska infektionsdata kan användas för att extrapolera epidemins beteende med statistiska modeller.
"På grund av osäkerheterna i båda parametrarna som är involverade i modellerna - infektionsfrekvens, inkubationsperiod och återhämtningstid – och ofullständigheten av infektionsdata inom olika länder, extrapolationer kan leda till ett otroligt stort antal osäkra resultat, " sa Faranda. "Till exempel, att bara anta en underskattning av de senaste uppgifterna i infektionsantalet på 20 % kan leda till en förändring av den totala infektionsuppskattningen från några tusen till några få miljoner individer."
Gruppen har också visat att denna osäkerhet beror på bristande datakvalitet och även på dynamikens inneboende natur, eftersom det är ultrakänsligt för parametrarna – särskilt under den inledande växtfasen. Detta innebär att alla bör vara mycket försiktiga med att extrapolera nyckelkvantiteter för att bestämma om de ska genomföra låsningsåtgärder när en ny våg av viruset börjar.
"Det totala antalet slutliga infektioner liksom epidemins varaktighet är känsliga för de uppgifter du lägger in, " han sa.
Teamets modell hanterar osäkerhet på ett naturligt sätt, så de planerar att visa hur modellering av fasen efter förlossningen kan vara känslig för de åtgärder som vidtas.
"Preliminära resultat visar att implementering av lockdown-åtgärder när infektioner är i en fullständig exponentiell tillväxtfas utgör allvarliga begränsningar för deras framgång, sa Faranda.