Kredit:CC0 Public Domain
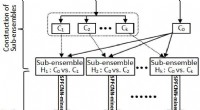
Ett forskarlag ledd av prof. LI Huiyun från Shenzhen Institutes of Advanced Technology (SIAT) vid den kinesiska vetenskapsakademin introducerade en enkel algoritm för djup förstärkning inlärning (DRL) med m-out-of-n bootstrap-teknik och aggregerad multipel djup deterministisk policygradient (DDPG) algoritmstrukturer.
Benämnd "bootstrapped aggregated multi-DDPG" (BAMDDPG), den nya algoritmen påskyndade träningsprocessen och ökade prestandan inom området intelligent artificiell forskning.
Forskarna testade sin algoritm på 2D-robot och öppen racingbilsimulator (TORCS). Experimentresultaten på 2D-robotarmspelet visade att belöningen som erhölls av den aggregerade policyn var 10–50 % bättre än de som erhölls av underpolicyer, och experimentresultat på TORCS visade att den nya algoritmen kunde lära sig framgångsrika kontrollpolicyer med mindre träningstid med 56,7 %.
DDPG-algoritm som arbetar över ett kontinuerligt handlingsutrymme har väckt stor uppmärksamhet för förstärkningsinlärning. Dock, Utforskningsstrategin genom dynamisk programmering inom det Bayesianska trostillståndsrummet är ganska ineffektiv även för enkla system. Detta leder vanligtvis till att standard bootstrap misslyckas när man lär sig en optimal policy.
Den föreslagna algoritmen använder den centraliserade uppspelningsbufferten för att förbättra utforskningseffektiviteten. M-out-of-n bootstrap med slumpmässig initiering ger rimliga osäkerhetsuppskattningar till låga beräkningskostnader, hjälpa till att konvergensen av utbildningen. Den föreslagna bootstrappade och aggregerade DDPG kan minska inlärningstiden.
BAMDDPG gör det möjligt för varje agent att använda erfarenheter från andra agenter. Detta gör utbildningen av underpolicyer för BAMDDPG mer effektiv eftersom varje agent äger en bredare vision och mer miljöinformation.
Denna metod är effektiv för sekventiell och iterativ träningsdata, där uppgifterna uppvisar långsvansad distribution, snarare än normfördelningen som impliceras av det oberoende identiskt fördelade dataantagandet. Den kan lära sig de optimala policyerna med mycket mindre träningstid för uppgifter med kontinuerligt utrymme för åtgärder och tillstånd.
Studien, med titeln "Deep Ensemble Reinforcement Learning with Multiple Deep Deep Deterministic Policy Gradient Algorithm, " publicerades i Hindawi .