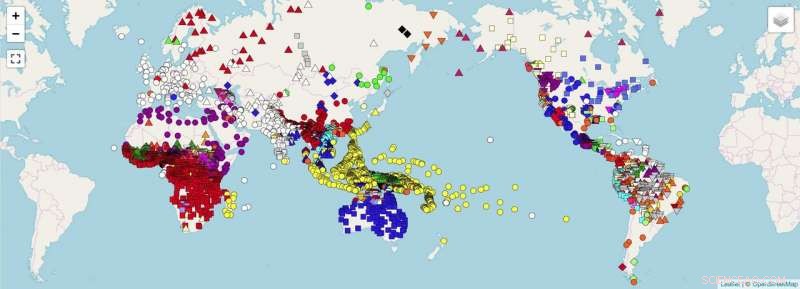
En världskarta som visar datapunkter, för vilka forskarna planerar att samla in enhetlig data (t.ex. data som är direkt jämförbara) med hjälp av riktlinjerna i uppsatsen. Kredit:OpenStreetMap. Forkel et al. 2018. Tvärspråkliga dataformat, främja datadelning och återanvändning inom jämförande lingvistik. Vetenskapliga data .
Ett internationellt team av forskare, medlemmar av Cross-Linguistic Data Formats Initiative (CLDF) som leds av Max Planck Institute for Science of Human History, har föreslagit nya riktlinjer för tvärspråkliga dataformat för att underlätta delning och datajämförelser mellan det växande antalet stora språkliga databaser över hela världen. Detta format tillhandahåller ett mjukvarupaket, en grundläggande ontologi och användningsexempel.
Det finns ett ökande antal språkliga databaser över hela världen, öka möjligheten till ett stort nätverk för potentiella jämförande studier. Dock, dessa databaser skapas vanligtvis oberoende av varandra, och har ofta ett unikt och smalt fokus. Detta innebär att formaten som används för att koda data ofta är olika, skapar svårigheter att jämföra data mellan databaser.
Cross-Linguistic Data Formats Initiative (CLDF) är ett försök att lösa dessa problem. I en tidning publicerad i Vetenskapliga data , CLDF anger föreslagna riktlinjer för ett standardiserat format för språkliga databaser, och levererar även ett mjukvarupaket, en grundläggande ontologi och användningsexempel på bästa praxis. Målet med denna satsning är att underlätta delning och återanvändning av data inom jämförande lingvistik.
CLDF tillhandahåller en datamodell som ligger till grund för dess rekommendationer som syftar till att vara enkel, ändå uttrycksfull, och bygger på den datamodell som tidigare utvecklats för projektet Cross-Linguistic Data. Denna modell har fyra huvudenheter:(a) Språk; (b) parametrar. (c) värden; och (d) källor. I modellen, varje värde är relaterat till en parameter och ett språk, och kan baseras på flera källor. Det finns dessutom referenser till källor, och referenser kan också ha sammanhang (som, till exempel, för tryckta referenser skulle vara sidnummer).
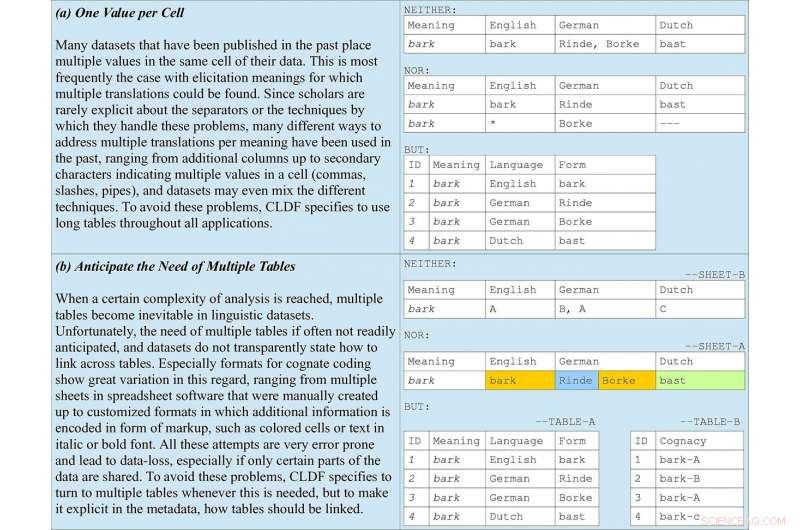
Grundläggande regler för datakodning som ingår i riktlinjerna, ta besläktad kodning i ordlistor som exempel. (a) illustrerar varför långa tabeller bör gynnas genom alla ansökningar. (b) understryker vikten av att förutse flera tabeller tillsammans med metadata som anger hur de bör länkas. Kredit:Forkel et al. 2018. Tvärspråkliga dataformat, främja datadelning och återanvändning inom jämförande lingvistik. Vetenskapliga data .
CLDF-datamodellen är ett paketformat där en datauppsättning skulle bestå av en uppsättning datafiler som innehåller tabeller, och en beskrivande fil som definierar relationerna mellan tabellerna. Varje språklig datatyp skulle ha en CLDF-modul och ytterligare komponenter, vilket skulle vara de aspekter av data i modulen som återkommer över flera datatyper. CLDF-modulerna skulle också innehålla termer från CLDF-ontologin. Ontologin är en lista över ordförråd som representerar objekt och egenskaper med välkänd semantik inom jämförande lingvistik. Detta gör det möjligt för användare att referera till dessa villkor på ett enhetligt sätt.
Ett mjukvarupaket för att möjliggöra validering och manipulation
CLDF-specifikationerna använder vanliga filformat – som CSV, JSON och BibTeX – som stöds brett, med målet att dessa filer lätt kan läsas och skrivas på många plattformar. Ännu viktigare, det standardiserade formatet kommer att tillåta forskare utan programmeringskunskaper att få tillgång till och manipulera data med redan existerande verktyg, att undvika att begränsa paketet enbart till forskare med tillräcklig programmeringskunskaper för att skapa sina egna verktyg. För att underlätta detta, CLDF har skapat en "kokboks"-förråd för skript för användning med CLDF-specifikationerna.
"Vi vill ge tillgång till dessa data och möjligheten att jämföra dem med så många forskare som möjligt, säger Johann-Mattis List från Max Planck Institute for Science of Human History. Robert Forkel, en av drivkrafterna bakom CLDF-initiativet, noterar också att CLDF-formatet inte är begränsat till enbart språkdata, men kan också innehålla databaser med kulturell och geografisk data, till exempel. "CLDF kan drastiskt underlätta testningen av frågor angående interaktionen mellan språkliga, kulturell, och miljöfaktorer i språklig och kulturell evolution."