Kredit:Nvidia
Målet:Att ändra 2-D-bilder till 3-D-modeller med hjälp av en speciell kodar-avkodararkitektur. Skådespelarna:Nvidia. Beröm:Ett smart utnyttjande av maskininlärning med fördelaktiga verkliga tillämpningar.
Paul Lilly in Het hårdvara var bland teknikbevakarna som noterade att sättet de gick från 2-D-till-3-D var nyheter. Det är ingen stor överraskning när vägen är den omvända – 3-D till 2-D – men "att skapa en 3-D-modell utan att mata ett system 3-D-data är mycket mer utmanande."
Lilly citerade Jun Gao, en i forskargruppen som arbetade med renderingsmetoden. "Detta är i princip första gången någonsin som du kan ta nästan vilken 2-D-bild som helst och förutsäga relevanta 3-D-egenskaper."
Deras magiska sås i att producera ett 3-D-objekt från 2-D-bilder är en "differentierbar interpolationsbaserad renderare, " eller DIB-R. Forskarna vid Nvidia tränade sin modell på datauppsättningar som inkluderade fågelbilder. Efter träning, DIB-R hade en förmåga att ta en fågelbild och leverera en 3D-skildring, med rätt form och struktur av en 3D-fågel.
Nvidia beskrev vidare indata som transformerats till en funktionskarta eller vektor som används för att förutsäga specifik information som form, Färg, textur och ljussättning av en bild.
Varför detta är viktigt: Gizmodo rubriken sammanfattade det. "Nvidia lärde en AI att omedelbart generera fulltexturerade 3D-modeller från platta 2D-bilder." Det ordet "omedelbart" är viktigt.
DIB-R kan producera ett 3D-objekt från en 2D-bild på mindre än 100 millisekunder, sa Nvidias Lauren Finkle. "Den gör det genom att ändra en polygonsfär - den traditionella mallen som representerar en 3D-form. DIB-R ändrar den för att matcha den verkliga objektformen som porträtteras i 2D-bilderna."
Andrew Liszewski in Gizmodo lyfte fram detta tidselement på 100 millisekunder. "Den imponerande bearbetningshastigheten är det som gör det här verktyget särskilt intressant eftersom det har potential att avsevärt förbättra hur maskiner gillar robotar, eller autonoma bilar, se världen, och förstå vad som ligger framför dem."
När det gäller autonoma bilar, Liszewski sa, "Stillbilder hämtade från en livevideoström från en kamera kan omedelbart konverteras till 3D-modeller som tillåter en autonom bil, till exempel, för att noggrant mäta storleken på en stor lastbil som den behöver undvika."

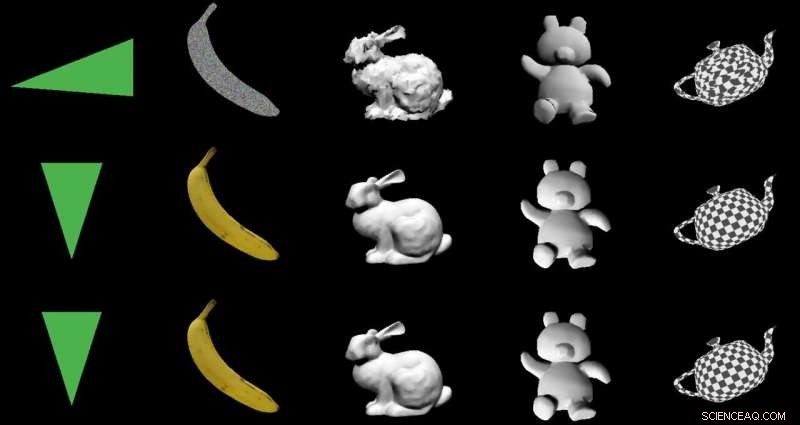
Teamet testade DIB-R på fyra 2D-bilder av fåglar (längst till vänster). Det första experimentet använde en bild av en gul sångare (överst till vänster) och producerade ett 3D-objekt (översta två raderna). Kredit:Nvidia
En modell som skulle kunna sluta sig till ett 3D-objekt från en 2D-bild skulle kunna utföra bättre objektspårning, och Lilly övergick till att tänka på dess användning inom robotik. "Genom att bearbeta 2D-bilder till 3D-modeller, en autonom robot skulle vara i en bättre position att interagera med sin omgivning säkrare och mer effektivt, " han sa.
Nvidia noterade att autonoma robotar, för att göra det, "måste kunna känna och förstå sin omgivning. DIB-R skulle potentiellt kunna förbättra dessa djupuppfattningsförmåga."
Gizmodo s Liszewski, under tiden, nämnde vad Nvidias tillvägagångssätt kan göra för säkerheten. "DIB-R kan till och med förbättra prestandan hos säkerhetskameror med uppgift att identifiera personer och spåra dem, eftersom en omedelbart genererad 3D-modell skulle göra det lättare att utföra bildmatchningar när en person rör sig genom sitt synfält."
Nvidia-forskare skulle presentera sin modell denna månad vid den årliga konferensen om neurala informationsbehandlingssystem (NeurIPS), i Vancouver.
De som vill lära sig mer om sin forskning kan kolla in deras uppsats på arXiv, "Lära sig att förutsäga 3D-objekt med en interpolationsbaserad differentierbar renderare." Författarna är Wenzheng Chen, Jun Gao, Huan Ling, Edward J. Smith, Jaakko Lehtinen, Alec Jacobson och Sanja Fidler.
De föreslog "en komplett rasteriseringsbaserad differentierbar renderare för vilken gradienter kan beräknas analytiskt." När den lindas runt ett neuralt nätverk, deras ram lärde sig att förutsäga form, textur, och ljus från enstaka bilder, de sa, och de visade upp sitt ramverk "för att lära sig en generator av 3D-texturerade former."
I sitt abstrakta, författarna observerade att "Många maskininlärningsmodeller fungerar på bilder, men ignorera det faktum att bilder är 2D-projektioner som bildas av 3D-geometri som interagerar med ljus, i en process som kallas rendering. Att göra det möjligt för ML-modeller att förstå bildbildning kan vara nyckeln till generalisering."
De presenterade DIB-R som ett ramverk som gör att gradienter kan beräknas analytiskt för alla pixlar i en bild.
De sa att nyckeln till deras tillvägagångssätt var "att se förgrundsrastrering som en viktad interpolation av lokala egenskaper och bakgrundsrastrering som en avståndsbaserad aggregering av global geometri. Vårt tillvägagångssätt möjliggör noggrann optimering över vertexpositioner, färger, normala, ljusriktningar och texturkoordinater genom en mängd olika belysningsmodeller."
© 2019 Science X Network