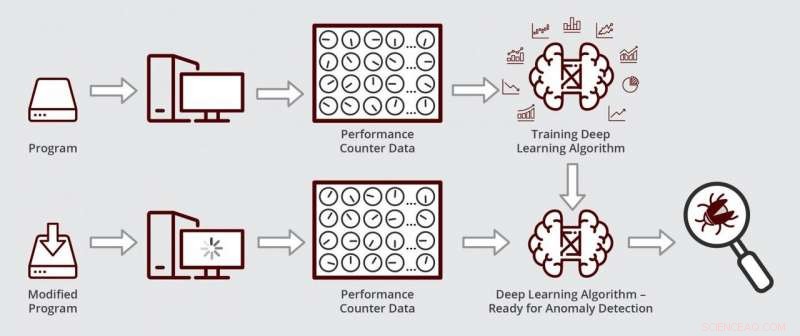
Schematisk illustration av hur Muzahids djupinlärningsalgoritm fungerar. Algoritmen är redo för anomalidetektering efter att den först tränats på prestandaräknaredata från en buggfri version av ett program. Kredit:Texas A&M Engineering
Vi har alla delat frustrationen – programuppdateringar som är avsedda att få våra applikationer att köras snabbare slutar oavsiktligt med att göra precis tvärtom. Dessa buggar, dubbade inom datavetenskapen som prestationsregressioner, är tidskrävande att åtgärda eftersom lokalisering av programvarufel normalt kräver betydande mänsklig inblandning.
För att övervinna detta hinder, forskare vid Texas A&M University, i samarbete med datavetare vid Intel Labs, har nu utvecklat ett helt automatiserat sätt att identifiera källan till fel orsakade av programuppdateringar. Deras algoritm, baserad på en specialiserad form av maskininlärning som kallas djupinlärning, är inte bara nyckelfärdig, men också snabbt, hitta prestandabuggar på några timmar istället för dagar.
"Att uppdatera mjukvara kan ibland slå på dig när fel smyger sig in och orsaka avmattning. Detta problem är ännu mer överdrivet för företag som använder storskaliga mjukvarusystem som ständigt utvecklas, " sa Dr Abdullah Muzahid, biträdande professor vid institutionen för datavetenskap och teknik. "Vi har designat ett bekvämt verktyg för att diagnostisera prestandaregressioner som är kompatibelt med en hel rad mjukvara och programmeringsspråk, utökar dess användbarhet enormt."
Forskarna beskrev sina resultat i den 32:a upplagan av Advances in Neural Information Processing Systems från konferensen om Neural Information Processing Systems i december.
För att lokalisera källan till fel i programvaran, felsökare kontrollerar ofta statusen för prestandaräknare inom den centrala bearbetningsenheten. Dessa räknare är kodrader som övervakar hur programmet körs på datorns hårdvara i minnet, till exempel. Så, när programvaran körs, räknare håller reda på hur många gånger den kommer åt vissa minnesplatser, tiden den stannar där och när den går ut, bland annat. Därav, när programvarans beteende går snett, räknare används återigen för diagnostik.
"Prestandaräknare ger en uppfattning om hur programmet körs, " sa Muzahid. "Så, om något program inte körs som det ska, dessa räknare kommer vanligtvis att ha ett tecken på avvikande beteende."
Dock, nyare stationära datorer och servrar har hundratals prestandaräknare, vilket gör det praktiskt taget omöjligt att hålla reda på alla deras statusar manuellt och sedan leta efter avvikande mönster som tyder på ett prestandafel. Det är där Muzahids maskininlärning kommer in.
Genom att använda djupinlärning, forskarna kunde övervaka data som kom från ett stort antal räknare samtidigt genom att minska storleken på data, vilket liknar att komprimera en högupplöst bild till en bråkdel av dess ursprungliga storlek genom att ändra dess format. I de lägre dimensionella data, deras algoritm kan sedan leta efter mönster som avviker från det normala.
När deras algoritm var klar, forskarna testade om det kunde hitta och diagnostisera en prestandabugg i en kommersiellt tillgänglig datahanteringsprogramvara som används av företag för att hålla reda på deras siffror och siffror. Först, de tränade sin algoritm att känna igen normal räknardata genom att köra en äldre, felfri version av programvaran för datahantering. Nästa, de körde sin algoritm på en uppdaterad version av programvaran med prestandaregression. De upptäckte att deras algoritm lokaliserade och diagnostiserade felet inom några timmar. Muzahid sa att denna typ av analys kan ta avsevärd tid om den görs manuellt.
Förutom att diagnostisera prestandaregressioner i programvara, Muzahid noterade att deras djupinlärningsalgoritm har potentiell användning inom andra forskningsområden också, som att utveckla den teknik som behövs för autonom körning.
"Grundtanken är återigen densamma, som är att kunna upptäcka ett avvikande mönster, " sade Muzahid. "Självkörande bilar måste kunna upptäcka om en bil eller en människa står framför den och sedan agera därefter. Så, det är återigen en form av anomalidetektering och den goda nyheten är att det är vad vår algoritm redan är designad för att göra."
Andra bidragsgivare till forskningen inkluderar Dr. Mejbah Alam, Dr. Justin Gottschlich, Dr Nesime Tatbul, Dr Javier Turek och Dr Timothy Mattson från Intel Labs.