Kredit:RUDN University
Matematiker från RUDN University och Free University of Berlin har föreslagit ett nytt tillvägagångssätt för att studera sannolikhetsfördelningarna av observerade data med hjälp av artificiella neurala nätverk. Det nya tillvägagångssättet fungerar bättre med så kallade outliers, dvs. indataobjekt som väsentligt avviker från det övergripande urvalet. Artikeln publicerades i tidskriften Artificiell intelligens .
Återställandet av sannolikhetsfördelningen av observerade data genom artificiella neurala nätverk är den viktigaste delen av maskininlärning. Sannolikhetsfördelningen tillåter oss inte bara att förutsäga beteendet hos systemet som studeras, men också för att kvantifiera den osäkerhet med vilken prognoser görs. Den största svårigheten är att i regel, endast data observeras, men deras exakta sannolikhetsfördelningar är inte tillgängliga. För att lösa det här problemet, Bayesianska och andra liknande ungefärliga metoder används. Men deras användning ökar komplexiteten i ett neuralt nätverk och gör därför träningen mer komplicerad.
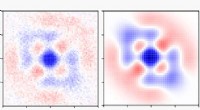
RUDN University och Free University of Berlins matematiker använde deterministiska vikter i neurala nätverk, som skulle hjälpa till att övervinna begränsningarna hos Bayesianska metoder. De utvecklade en formel som gör att man korrekt kan uppskatta variansen i fördelningen av observerade data. Den föreslagna modellen testades på olika data:syntetiska och verkliga; om uppgifter som innehåller extremvärden och om uppgifter från vilka extremvärdena tagits bort. Den nya metoden tillåter återställning av sannolikhetsfördelningar med en noggrannhet som tidigare inte varit möjlig.
Matematikerna vid RUDN University och Free University of Berlin använde deterministiska vikter för neurala nätverk och använde nätverkets utdata för att koda fördelningen av latenta variabler för den önskade marginalfördelningen. En analys av träningsdynamiken i sådana nätverk gjorde det möjligt för dem att få en formel som korrekt uppskattar variansen av observerade data, trots förekomsten av extremvärden i uppgifterna. Den föreslagna modellen testades på olika data:syntetiska och verkliga. Den nya metoden gör det möjligt att återställa sannolikhetsfördelningar med högre noggrannhet jämfört med andra moderna metoder. Noggrannheten bedömdes med hjälp av AUC-metoden (area under kurvan är arean under grafen som gör det möjligt att bedöma medelkvadratfelet för förutsägelserna beroende på provstorleken uppskattad av nätverket som "tillförlitlig"; ju högre AUC-poäng, desto bättre förutsägelser).