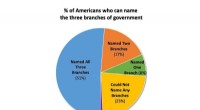
OI började arkeologiska expeditioner till den antika staden Persepolis på 1930-talet, där de avslöjade tiotusentals lertavlor innehållande kilskrift. Ett samarbete mellan OI och Institutionen för datavetenskap med hjälp av ett maskininlärningsprogram skulle kunna möjliggöra snabbare översättning av dessa surfplattor. Kredit:OI
För tjugofem århundraden sedan, "pappersarbetet" från Persiens akemenidiska rike registrerades på lertavlor – tiotusentals av dessa upptäcktes 1933 i dagens Iran av arkeologer från University of Chicagos Oriental Institute. I årtionden, forskare har noggrant studerat och översatt dessa gamla dokument för hand, men den här manuella dechiffreringsprocessen är mycket svår, långsam och risk för fel.
Sedan 1990-talet, forskare har rekryterat datorer för att hjälpa — med begränsad framgång, på grund av tabletternas tredimensionella karaktär och kilskriftsfigurernas komplexitet. Men ett tekniskt genombrott vid University of Chicago kan äntligen göra automatiserad transkription av dessa tabletter – som avslöjar rik information om Achaemenidernas historia, samhälle och språk – möjligt, frigöra arkeologer för analys på högre nivå.
Det är motivationen bakom DeepScribe, ett samarbete mellan forskare från OI och UChicagos institution för datavetenskap. Med ett träningsset på mer än 6, 000 kommenterade bilder från Persepolis Fortification Archive, det Center for Data and Computing-finansierade projektet kommer att bygga en modell som kan "läsa" ännu inte analyserade surfplattor i samlingen, och potentiellt ett verktyg som arkeologer kan anpassa till andra studier av forntida skrift.
"Om vi kunde komma på ett verktyg som är flexibelt och utbyggbart, som kan spridas till olika skript och tidsperioder, det skulle verkligen förändra fältet, sa Susanne Paulus, docent i assyriologi.
"Det är ett bra maskininlärningsproblem"
Samarbetet började när Paulus, Sandra Schloen och Miller Prosser från OI träffade Asst. Prof. Sanjay Krishnan vid institutionen för datavetenskap vid ett Neubauer Collegium-evenemang om digital humaniora. Schloen och Prosser övervakar OCHRE, en databashanteringsplattform som stöds av OI för att fånga och organisera data från arkeologiska utgrävningar och andra former av forskning. Krishnan tillämpar djupinlärning och AI-tekniker för dataanalys, inklusive video och andra komplexa datatyper. Överlappningen var omedelbart uppenbar för båda sidor.
"Från datorseendet, det är verkligen intressant eftersom det är samma utmaningar som vi står inför. Datorseendet under de senaste fem åren har förbättrats så avsevärt; tio år sedan, detta skulle ha varit handvågigt, vi skulle inte ha kommit så långt, " sa Krishnan. "Det är ett bra maskininlärningsproblem, eftersom noggrannheten är objektiv här, vi har ett märkt träningsset och vi förstår manuset ganska bra och det hjälper oss. Det är inte ett helt okänt problem."

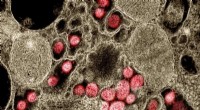
På bilden är hotspots som visar kilskriftsskyltar på en Elamite-tavla från Persepolis Fortification Archive. Kredit:OI
Det utbildningssetet är tack vare mer än 80 års nära studier av OI- och UChicago-forskare och en nyligen genomförd insats för att digitalisera högupplösta bilder av surfplattsamlingen – för närvarande över 60 terabyte och fortfarande växande – innan de återvände till Iran. Genom att använda denna samling, forskare skapade en ordbok över det elamitiska språket inskrivet på tabletterna, och studenter som lärde sig dechiffrera kilskrift byggde en databas med mer än 100, 000 "hotspots, " eller identifierade individuella tecken.
Med resurser från UChicago Research Computing Center, Krishnan använde denna kommenterade datauppsättning för att träna en maskininlärningsmodell, liknande de som används i andra datorseendeprojekt. När den testas på surfplattor som inte ingår i träningssetet, modellen kunde framgångsrikt dechiffrera kilskriftstecken med cirka 80 % noggrannhet. Pågående forskning kommer att försöka lyfta den siffran högre samtidigt som man undersöker vad som står för de återstående 20 %.
Mycket digitala tunga lyft
Men till och med 80 % noggrannhet kan omedelbart ge hjälp för transkriptionsinsatser. Många av surfplattorna beskriver grundläggande kommersiella transaktioner, liknande "en låda med Walmart-kvitton, " sa Paulus. Och ett system som inte riktigt kan bestämma sig kan fortfarande vara användbart.
"Om datorn bara kunde översätta eller identifiera de mycket repetitiva delarna och överlåta till en expert att fylla i de svåra ortnamnen eller verben eller saker som behöver tolkas, som får mycket av arbetet gjort, sade Paulus, Tablet Collection Curator vid OI. "Och om datorn inte kan fatta ett definitivt beslut, om det kunde ge oss tillbaka sannolikheterna eller de fyra bästa rankningarna, då har en expert en plats att börja. Det skulle vara fantastiskt."
Ännu mer ambitiöst, teamet föreställer sig DeepScribe som ett allmänt dechiffreringsverktyg som de kan dela med andra arkeologer. Kanske kan modellen omskolas till andra kilskriftsspråk än elamitiska, eller kan ge utbildade förslag om vilken text som skrevs på saknade bitar av ofullständiga surfplattor. En maskininlärningsmodell kan också hjälpa till att fastställa ursprunget för surfplattor och andra artefakter av okänd härkomst, en uppgift som för närvarande behandlas av kemisk testning.
Liknande CDAC-finansierade projekt använder datorseende för applikationer, som att studera biologisk mångfald hos marina musslor och att lösa stil från innehåll i konstnärligt arbete. Samarbetet hoppas också kunna inspirera framtida partnerskap mellan OI och Institutionen för datavetenskap, i takt med att digital arkeologi i allt högre grad korsar sig med avancerade beräkningsmetoder.
"Jag tror att det hjälpte något som skulle ha slutat vid ett middagssamtal blivit ett verkligt samarbete, " sa Krishnan. "Det fick oss att göra mer än att prata."