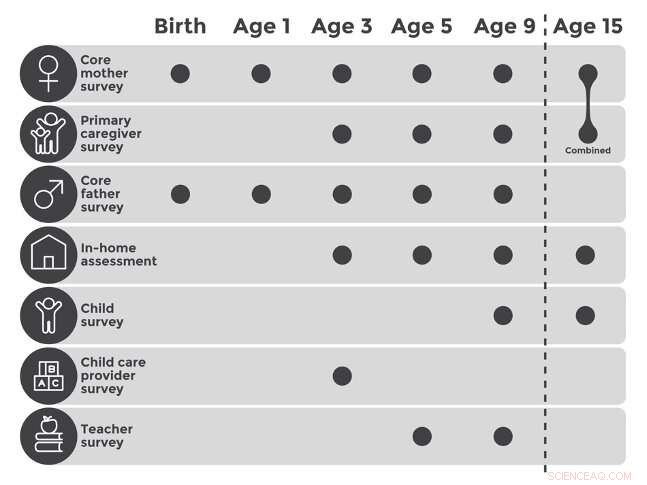
Fragile Families-studien fångade information om barn vid födseln och i åldrarna 1, 3, 5, 9 och 15. Denna information fångades in genom en mängd olika undersökningar, listade till vänster om dessa åldrar i diagrammet ovan. Fragile Families Challenge använde data från våg ett till fem för att förutsäga utfall i våg sex. Kredit:Matthew Salganik et al. 2020, Princeton Universitet
Maskininlärningsteknikerna som forskare använder för att förutsäga resultat från stora datamängder kan misslyckas när det gäller att projicera resultaten av människors liv, enligt en massstudie ledd av forskare vid Princeton University i ett samarbete med forskare från många institutioner, inklusive Virginia Tech.
Detta masssamarbete, kallad Fragile Families Challenge, representerar en kohort av forskare som bygger statistiska modeller och modeller för maskininlärning för att förutsäga och mäta livsresultat för barn, föräldrar, och hushåll över hela USA.
Publicerad av 112 medförfattare i Förfaranden från National Academy of Sciences , resultaten tyder på att sociologer och datavetare bör vara försiktiga när de använder prediktiv modellering, särskilt i det straffrättsliga systemet och sociala program.
Även efter att ha använt toppmodern modellering och en högkvalitativ datauppsättning som innehåller 13, 000 datapunkter för mer än 4, 000 familjer, de bästa AI-prediktiva modellerna var inte särskilt exakta.
Brian J. Goode, en forskare från Virginia Techs Fralin Life Sciences Institute, var bland de data- och samhällsvetare som deltog i Fragile Families Challenge.
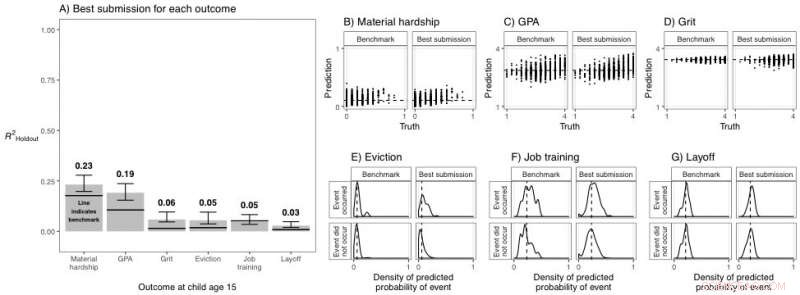
Figur A visar skillnaden mellan de bästa bidragen för varje resultat jämfört med benchmarkmodellen. Figur B-G jämförde förutsägelserna och sanningen för varje resultat. Kredit:Matthew Salganik et al. 2020, Princeton Universitet
"Det är ett försök att försöka fånga komplexiteten och krångligheterna som utgör strukturen i ett mänskligt liv i data och modeller. Men, det är obligatoriskt att ta nästa steg och kontextualisera modeller i termer av hur de ska tillämpas för att bättre kunna resonera kring förväntade osäkerheter och begränsningar av en förutsägelse. Det är ett väldigt svårt problem att ta itu med, och jag tror att Fragile Families Challenge visar att vi behöver mer forskningsstöd inom detta område, särskilt eftersom maskininlärning har en större inverkan på vår vardag, " sa Goode.Goodes modellering genomfördes genom Discovery Analytics Center vid Virginia Tech. Där, han slog sig ihop med Discovery Analytics Centers chef och Thomas L. Phillips professor i teknik, Naren Ramakrishnan, och Debanjan Datta, en doktorsexamen student vid Institutionen för datavetenskap vid Tekniska Högskolan, som var avgörande för att samla in och analysera data.
Virginia Tech-teamet har också publicerat forskning i ett specialnummer av Socius, en ny tidskrift med öppen tillgång från American Sociological Association. För att stödja ytterligare forskning inom detta område, alla bidrag till utmaningen—kod, förutsägelser och narrativa förklaringar – är offentligt tillgängliga.
"Studien visar oss också att vi har så mycket att lära, och masssamarbeten som detta är oerhört viktiga för forskarsamhället, " sa PNAS-studiens medförfattare Matt Salganik, professor i sociologi vid Princeton och tillfällig chef för Center for Information Technology Policy, baserad på Princetons Woodrow Wilson School of Public and International Affairs.
Projektet är inspirerat av Wikipedia, ett av världens första masssamarbeten, som skapades 2001 som ett delat uppslagsverk. Salganik funderade på vilka andra vetenskapliga problem som skulle kunna lösas genom en ny form av samarbete, och det var då han gick ihop med Sara McLanahan, William S. Tod professor i sociologi och offentliga angelägenheter vid Princeton, samt Princeton-studenterna Ian Lundberg och Alex Kindel, båda på sociologiska institutionen.
McLanahan är huvudutredare för Fragile Families and Child Wellbeing Study baserad vid Princeton och Columbia University, som har studerat en kohort på cirka 5, 000 barn födda i stora amerikanska städer mellan 1998 och 2000, med ett översampling av barn födda av ogifta föräldrar. Den longitudinella studien utformades för att förstå livet för barn som föds i ogifta familjer.
Genom undersökningar insamlade i sex vågor (när barnet föddes och sedan när barnet nådde 1 års ålder, 3, 5, 9, och 15), studien har fångat miljontals datapunkter om barn och deras familjer. Ytterligare en våg kommer att fångas vid 22 års ålder.
När forskarna utformade utmaningen, data från 15 års ålder (som forskarna i tidningen kallar "hålla-ut-data) hade ännu inte gjorts offentligt tillgängliga. Detta skapade en möjlighet att be andra forskare att förutsäga livsresultatet för människorna i studien genom ett masssamarbete.

160 forskargrupper av data- och samhällsvetare byggde statistiska modeller och modeller för maskininlärning för att förutsäga mäta sex livsutfall för barn, föräldrar, och hushåll. Även efter att ha använt en toppmodern modellering och en högkvalitativ datauppsättning som innehåller 13, 000 datapunkter om mer än 4, 000 familjer, de bästa AI-prediktiva modellerna var inte särskilt exakta. Kredit:Egan Jimenez, Princeton Universitet
Medarrangörerna fick 457 ansökningar från 68 institutioner från hela världen, inklusive från flera team baserade på Princeton. Genom att använda data från Fragile Familjer, deltagarna ombads att förutsäga ett eller flera av de sex livsresultaten vid 15 års ålder. Dessa inkluderade medelvärde för barns betyg (GPA); barn grus; vräkning av hushåll; hushållsmateriella svårigheter; uppsägning av primärvårdare; och primärvårdarens deltagande i arbetsträning.
Utmaningen var baserad på den gemensamma uppgiftsmetoden, en forskningsdesign som används ofta inom datavetenskap men inte inom samhällsvetenskap. Denna metod släpper en del men inte all data, låta människor använda vilken teknik de vill för att bestämma resultat. Målet är att exakt förutsäga håll-out-data, oavsett hur fancy en teknik det krävs för att nå dit.
Teamet ansöker för närvarande om anslag för att fortsätta forskningen inom detta område.
Pappret, "Mäta förutsägbarheten av livsresultat med ett vetenskapligt masssamarbete, " publicerades den 30 mars av PNAS .