Forskare använde maskininlärning för att skapa den första storskaliga, datadriven studie för att belysa hur kultur påverkar ordens betydelser. Kredit:Målning av Babels torn av Pieter Bruegel den äldre, Konsthistoriska Museum Wien, Wien, Österrike
Vad menar vi med ordet vacker? Det beror inte bara på vem du frågar, men på vilket språk du frågar dem. Enligt en maskininlärningsanalys av dussintals språk utförd vid Princeton University, betydelsen av ord hänvisar inte nödvändigtvis till en inneboende, väsentlig konstant. Istället, det är väsentligt format av kultur, historia och geografi. Detta fynd gällde även för vissa begrepp som verkar vara universella, såsom känslor, landskapsdrag och kroppsdelar.
"Även för varje dag ord som du skulle tro betyder samma sak för alla, det finns all denna variation där ute, sa William Thompson, en postdoktor i datavetenskap vid Princeton University, och huvudförfattare till fynden, publicerad i Natur Mänskligt beteende 10 augusti. "Vi har tillhandahållit de första datadrivna bevisen på att sättet vi tolkar världen genom ord är en del av vårt kulturarv."
Språket är prismat genom vilket vi konceptualiserar och förstår världen, och lingvister och antropologer har länge försökt reda ut de komplexa krafter som formar dessa kritiska kommunikationssystem. Men studier som försöker ta itu med dessa frågor kan vara svåra att genomföra och tidskrävande, involverar ofta långa, noggranna intervjuer med tvåspråkiga talare som utvärderar kvaliteten på översättningar. "Det kan ta år och år att dokumentera ett specifikt par språk och skillnaderna mellan dem, Thompson sa. "Men maskininlärningsmodeller har nyligen dykt upp som gör att vi kan ställa dessa frågor med en ny nivå av precision."
I deras nya tidning, Thompson och hans kollegor Seán Roberts vid University of Bristol, STORBRITANNIEN., och Gary Lupyan från University of Wisconsin, Madison, utnyttjade kraften i dessa modeller för att analysera över 1, 000 ord på 41 språk.
Istället för att försöka definiera orden, den storskaliga metoden använder begreppet "semantiska associationer, " eller helt enkelt ord som har en meningsfull relation till varandra, vilket lingvister tycker är ett av de bästa sätten att definiera ett ord och jämföra det med ett annat. Semantiska bekanta med "vacker, " till exempel, inkluderar "färgglada, " "kärlek, " "dyrbar" och "känslig."
Forskarna byggde en algoritm som undersökte neurala nätverk tränade på olika språk för att jämföra miljontals semantiska associationer. Algoritmen översatte de semantiska associerade till ett visst ord till ett annat språk, och sedan upprepade processen tvärtom. Till exempel, algoritmen översatte de semantiska associerade med "beautiful" till franska och översatte sedan de semantiska associates av beau till engelska. Algoritmens slutliga likhetspoäng för ett ords betydelse kom från att kvantifiera hur nära semantiken stämmer överens i båda riktningarna av översättningen.
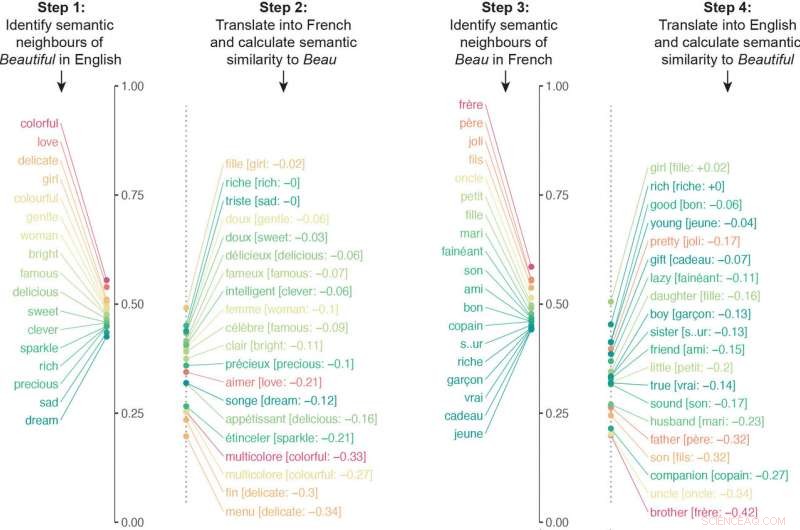
Algoritmen översatte de semantiska associerade till ett visst ord till ett annat språk, och sedan upprepade processen tvärtom. I det här exemplet, de semantiska grannarna till "beautiful" översattes till franska och sedan översattes de semantiska grannarna till "beau" till engelska. De respektive listorna var väsentligt olika på grund av olika kulturföreningar. Bild med tillstånd från forskarna. Kredit:Princeton University
"Ett sätt att se på vad vi har gjort är ett datadrivet sätt att kvantifiera vilka ord som är mest översättbara, "Sa Thompson.
Resultaten avslöjade att det finns några nästan universellt översättbara ord, främst de som hänvisar till siffror, yrken, kvantiteter, kalenderdatum och släktskap. Många andra ordtyper, dock, inklusive de som avser djur, mat och känslor, var mycket mindre väl matchade i betydelse.
I ett sista steg, forskarna använde en annan algoritm som jämförde hur lika de kulturer som producerade de två språken är, baserat på en antropologisk datauppsättning som jämför saker som äktenskapspraxis, rättssystem och politisk organisation av givna språks talare.
Forskarna fann att deras algoritm korrekt kunde förutsäga hur lätt två språk skulle kunna översättas baserat på hur lika de två kulturerna som talar dem är. Detta visar att variationen i ordets betydelse inte bara är slumpmässig. Kultur spelar en stark roll i att forma språk - en hypotes som teorin länge har förutspått, men att forskarna saknade kvantitativ data att stödja.
"Detta är ett extremt trevligt papper som ger en principiell kvantifiering av frågor som har varit centrala för studiet av lexikal semantik, sa Damián Blasi, en språkvetare vid Harvard University, som inte var involverad i den nya forskningen. Även om tidningen inte ger ett definitivt svar på alla de krafter som formar skillnaderna i ordets betydelse, metoderna som författarna etablerade är sunda, Blasi sa, och användningen av flera, olika datakällor "är en positiv förändring inom ett område som systematiskt har ignorerat kulturens roll till förmån för mentala eller kognitiva universal."
Thompson höll med om att han och hans kollegors resultat betonar värdet av att "kurera osannolika uppsättningar av data som normalt inte ses under samma omständigheter." De maskininlärningsalgoritmer han och hans kollegor använde tränades ursprungligen av datavetare, medan de datamängder som de matade in i modellerna för att analysera skapades av 1900-talets antropologer såväl som av nyare språkliga och psykologiska studier. Som Thompson sa, "Bakom dessa fina nya metoder, Det finns en hel historia av människor inom flera områden som samlar in data som vi sammanför och tittar på på ett helt nytt sätt."