Kredit:CC0 Public Domain
Den 3 nov. 2020 – och i många dagar efter – höll miljontals människor ett försiktigt öga på modellerna för att förutsäga presidentvalet som drivs av olika nyhetskanaler. Med så höga insatser i spel, varje tick av en sammanställning och ryck i en graf kan skicka chockvågor av övertolkning.
Ett problem med råa sammanställningar av presidentvalet är att de skapar en falsk berättelse om att slutresultaten fortfarande utvecklas på drastiska sätt. I verkligheten, på valnatten finns det ingen "att komma ikapp bakifrån" eller "tappa ledningen" eftersom rösterna redan är avgivna; vinnaren har redan vunnit – vi vet det bara inte än. Mer än att bara vara oprecis, dessa fängslande beskrivningar av röstningsprocessen kan få resultatet att verka överdrivet misstänksamt eller överraskande.
"Prediktiva modeller används för att fatta beslut som kan få enorma konsekvenser för människors liv, sa Emmanuel Candès, Barnum-Simons lärostol i matematik och statistik vid School of Humanities and Sciences vid Stanford University. "Det är oerhört viktigt att förstå osäkerheten kring dessa förutsägelser, så att folk inte fattar beslut baserade på falska övertygelser."
Sådan osäkerhet var precis vad Washington Post dataforskaren Lenny Bronner hade som mål att i en ny förutsägelsemodell lyfta fram som han började utveckla för lokala Virginia-val 2019 och förfinade ytterligare för presidentvalet, med hjälp av John Cherian, en nuvarande Ph.D. student i statistik på Stanford som Bronner kände från sina grundutbildningar.
"Modellen handlade egentligen om att lägga till sammanhang till resultaten som visades, ", sa Bronner. "Det handlade inte om att förutsäga valet. Det handlade om att berätta för läsarna att resultaten de såg inte reflekterade var vi trodde att valet skulle hamna."
Denna modell är den första verkliga tillämpningen av en befintlig statistisk teknik utvecklad på Stanford av Candès, före detta postdoktor Yaniv Romano och före detta doktorand Evan Patterson. Tekniken är tillämpbar på en mängd olika problem och, som i Postens predikationsmodell, skulle kunna bidra till att lyfta vikten av ärlig osäkerhet i prognoser. Medan Posten fortsätter att finjustera sin modell för framtida val, Candès tillämpar den underliggande tekniken någon annanstans, inklusive uppgifter om covid-19.
Undviker antaganden
För att skapa denna statistiska teknik, Candès, Romano och Evan Patterson kombinerade två forskningsområden - kvantilregression och konform förutsägelse - för att skapa vad Candès kallade "det mest informativa, välkalibrerat utbud av förutsagda värden som jag vet hur man bygger."
Medan de flesta förutsägelsemodeller försöker förutsäga ett enda värde, ofta medelvärdet (genomsnittet) av en datauppsättning, kvantilregression uppskattar en rad rimliga utfall. Till exempel, en person kanske vill hitta den 90:e kvantilen, vilket är den tröskel under vilken det observerade värdet förväntas falla 90 procent av tiden. När den läggs till kvantilregression, konform förutsägelse – utvecklad av datavetaren Vladimir Vovk – kalibrerar de uppskattade kvantilerna så att de är giltiga utanför ett prov, såsom för hittills osynliga data. För Postens valmodell, det innebar att man använde röstningsresultat från demografiskt liknande områden för att hjälpa till att kalibrera förutsägelser om röster som var utestående.
Det som är speciellt med denna teknik är att den börjar med minimala antaganden inbyggda i ekvationerna. För att arbeta, dock, det måste börja med ett representativt urval av data. Det är ett problem för valnatten eftersom den första rösträkningen - vanligtvis från små samhällen med mer personlig röstning - sällan återspeglar det slutliga resultatet.
Utan tillgång till ett representativt urval av nuvarande röster, Bronner och Cherian var tvungna att lägga till ett antagande. De kalibrerade sin modell med hjälp av röstsiffrorna från presidentvalet 2016 så att när ett område rapporterade 100 procent av sina röster, Postens modell skulle anta att alla förändringar mellan det områdets 2020 röster och dess 2016 röster skulle återspeglas lika i liknande län. (Modellen skulle sedan justera ytterligare – vilket minskade antagandets inflytande – eftersom fler områden rapporterade 100 procent av sina röster.) För att kontrollera giltigheten av denna metod, de testade modellen vid varje presidentval, med början 1992, och fann att dess förutsägelser nära överensstämde med de verkliga resultaten.
"Det som är trevligt med att använda Emmanuels inställning till detta är att felstaplarna runt våra förutsägelser är mycket mer realistiska och vi kan upprätthålla minimala antaganden, sa Cherian.
Visualisera osäkerhet
I aktion, Visualiseringen av Postens livemodell var noggrant utformad för att tydligt visa dessa felstaplar och den osäkerhet de representerade. The Post körde modellen för att prognostisera omfattningen av sannolika valresultat i olika delstater och länstyper; länen kategoriserades efter deras demografi. I alla fall, varje nominerad hade sin egen horisontella stapel som fylldes i fast — blått för Joe Biden, rött för Donald Trump – för att visa kända röster. Sedan, resten av stapeln innehöll en gradient som representerade de mest sannolika utfallen för de utestående rösterna, enligt modellen. Det mörkaste området av gradienten var det mest sannolika resultatet.
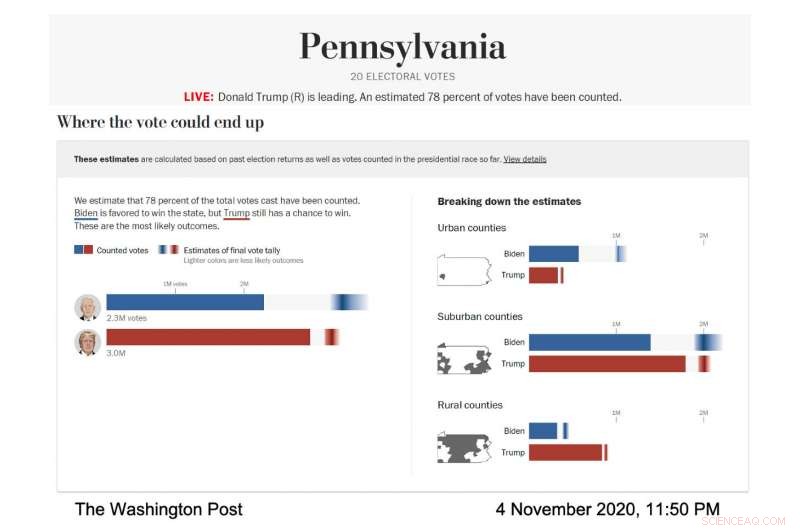
Skärmdump av valmodellen i Washington Post, visar röstningsprognosen för Pennsylvania den 4 november, 2020. (Bildkredit:med tillstånd av The Washington Post)
"Vi pratade med forskare om visualisering av osäkerhet och vi lärde oss att om du ger någon en genomsnittlig förutsägelse och sedan berättar för dem hur mycket osäkerhet det handlar om, de tenderar att ignorera osäkerheten, " sa Bronner. "Så vi gjorde en visualisering som är mycket "osäkerhet framåt." Vi ville visa, det här är osäkerheten och vi kommer inte ens att berätta vad vår genomsnittliga förutsägelse är."
När valnatten fortsatte, den mörkaste delen av Bidens gradient i den totala röstvisualiseringen var längre till höger sida av stapeln, vilket innebar att modellen förutspådde att han skulle få fler röster. Hans lutning var också bredare och spred sig asymmetriskt mot den högre röstsidan av stapeln, vilket innebar att modellen förutspådde att det fanns många scenarier, med bra odds, där han skulle vinna fler röster än det troligaste antalet.
"På valnatten vi märkte att felstaplarna var mycket korta på vänster sida av Bidens bar och mycket långa på höger sida, " sa Cherian. "Detta berodde på att Biden hade en hel del uppsida för att potentiellt överträffa vår prognose på ett väsentligt sätt och han hade inte så mycket nackdelar." . Eftersom modellens prognoser kalibrerades med hjälp av resultat från demografiskt likartade län som hade rapporterat sina röster, det blev tydligt att Biden hade en god chans att avsevärt överträffa 2016 års demokratiska omröstning i förortslän, medan det var extremt osannolikt att han skulle göra det sämre.
Självklart, när rösträkningen gick mot mål, gradienterna krympte och Postens osäkra förutsägelser såg allt säkrare ut – en nervkittlande situation för datavetare som är oroliga för att överdriva sådana viktiga slutsatser.
"Jag var särskilt orolig att loppet skulle komma ner till ett tillstånd, och vi skulle ha en förutsägelse på vår sida för dagar som inte gick i uppfyllelse, sa Bronner.
Och den oron var välgrundad eftersom modellen starkt och envist förutspådde en Biden-vinst i flera dagar när de slutgiltiga rösterna smög sig in från inte en stat, men tre:Wisconsin, Michigan och Pennsylvania.
"Det slutade med att han vann dessa stater, so that ended up working well for the model, " added Bronner. "But at the time it was very, very stressful."
Following their commitment to transparency, Bronner and Cherian also made the code to their election model public, so people can run it themselves. They've also published technical reports on their methods (available for download here). The model will run again during Virginia state elections this year and the midterm elections in 2022.
"We wanted to make everything public. We want this to be a conversation with people who care about elections and people who care about data, " said Bronner.
Forcing honesty
The bigger picture for Candès is how honest and transparent statistical work can contribute to more reasonable and ethical outcomes in the real world. Statistics, trots allt, are foundational to artificial intelligence and algorithms, which are pervasive in our everyday lives. They orchestrate our search results, social media experience and streaming suggestions while also being used in decision-making tools in medical care, university admissions, the justice system and banking. The power—and perceived omnipotence—of algorithms troubles Candès.
Models like the one the Post used can address some of these concerns. By starting with fewer assumptions, the model provides a more honest—and harder to overlook—assessment of the uncertainty surrounding its predictions. And similar models could be developed for a wide variety of prediction problems. Faktiskt, Candès is currently working on a model, built on the same statistical technique as the Post's election model, to infer survival times after contracting COVID-19 on the basis of relevant factors such as age, sex and comorbidities.
The catch to an honest, assumption-free statistical model, dock, is that the conclusions suffer if there isn't enough data. Till exempel, predictions about the consequences of different medical care decisions for women would have much wider error bars than predictions regarding men because we know far less about women, medically, than men.
This catch is a feature, fastän, not a bug. The uncertainty is glaringly obvious and so is the fix:We need more and better data before we start using it to inform important decisions.
"As statisticians, we want to inform decisions, but we're not decision makers, " Candès said. "So I like the way this model communicates the results of data analysis to decision makers because it's extremely honest reporting and avoids positioning the algorithm as the decision maker."