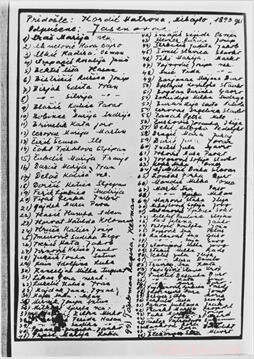
En av över 7, 000 listor med namn från koncentrationsläger i U.S. Holocaust Memorial Museum. Den här är en handskriven lista över serbiska och kroatiska kvinnor som deporterades till koncentrationslägret Jasenovac. Kredit:United States Holocaust Memorial Museum
Melkior Ornik, som är fakultetsmedlem för flygteknik, är också matematiker, en historiefantast, och en stark tro på integritet när det gäller att använda hård vetenskap i offentliga diskussioner. Så, när en berättelse dök upp i hans nyhetsflöde om ett par forskare som utvecklade en statistisk metod för att analysera datamängder och använde den för att påstås motbevisa antalet offer för Förintelsen från ett koncentrationsläger i Kroatien, det fångade naturligtvis hans uppmärksamhet.
Ornik är professor vid institutionen för flygteknik vid University of Illinois Urbana-Champaign. Han fortsatte med att studera forskningen på djupet och använde metoden för att analysera samma data från United States Holocaust Memorial Museum. Sedan skrev han ett motbevis som avslöjade forskarnas resultat.
Orniks genmäle publiceras i samma tidskrift som originalartikeln. Han sa att redaktören bad honom att inkludera en lista med svar på några av de potentiella frågor som andra forskare kan ha när de läser hans tidning. Några veckor senare, tidskriften placerade en anteckning om originalartikeln om att de inte stöder eller delar författarnas åsikter, och rekommenderade att läsa Orniks tidning.
"Som vetenskapsmän, som ingenjörer, Jag tror att det är vår plikt att rätta till felaktig och felaktig vetenskap, " sa Ornik. "Det är så mycket ansträngning att få allmänheten och beslutsfattare att tro på vetenskapen, att när en matematikexpert säger att de har bevis, det ger trovärdighet åt argumentet. Men när deras påståenden bevisligen inte är sanna, det är inte bra för vetenskapen och det är inte bra för samhället. Det är därför det är särskilt viktigt för forskare att utmana falska fynd när vi upptäcker dem."
Enligt Ornik, vissa individer främjar uppfattningen att koncentrationsläger antingen inte existerade eller inte användes för att döda människor, eller att det för närvarande allmänt accepterade antalet offer har ökat kraftigt. De flesta historiker tar inte påståendena på allvar i ljuset av omfattande tillgängliga data och bevis.
"Att författarna till den ursprungliga artikeln hävdar att de har hittat matematiska bevis för att listan över offren för det lägret tillverkades har uppenbara historiska implikationer, " sa Ornik. "Jag tror, till viss del har skadan redan skett, men jag kände ett behov av att gå på rekord med antagandena, felaktigheter, och missbruk av de råa museidata som jag hittade i den ursprungliga forskningen."
Tidningen Ornik svarade på presenterar en ny metod för att identifiera anomalier över en uppsättning histogram. Ornik sa att han inte ifrågasätter fördelarna med metoden som presenterades i det ursprungliga dokumentet, bara dess tillämpning på koncentrationslägret Jasenovac.
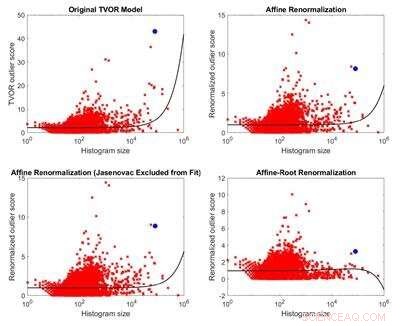
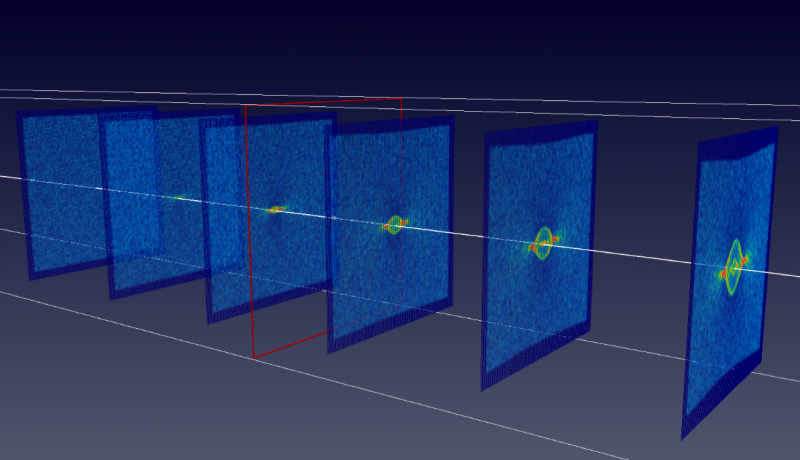
Jämförelse av den ursprungliga modellen för avvikande identifiering och tre modeller härledda från den. På grund av att dess antaganden inte är tillämpliga på den övervägda datamängden, den ursprungliga modellen har ingen teoretisk grund. Tre alternativa modeller är mindre partiska i storlek än den ursprungliga modellen och ger motsatta resultat. Kredit:Melkior Ornik
Ornik blev misstänksam mot tidningens slutsatser eftersom forskarna i ett fall antydde att en mindre lista naturligtvis har ett mindre extremvärde, men de jämförde poäng mellan offerlistans storlekar för att hävda att den relaterade till Jasenovac, en av de största, var problematiskt.
"Jag började leta för att se om det fanns någon slags snedvridning för storleken och om de faktiskt var mer benägna att tilldela flaggan att vara problematiska till en större lista eller inte. Och det visar sig, trots författarnas påståenden, de var, " Ornik sa. "De större listorna är mer benägna att beräknas vara problematiska än de mindre listorna när deras metod tillämpas på data."
Ornik, som vanligtvis använder liknande statistisk analys i flygtillämpningar, förklarade en annan anledning till att deras statistiska argument inte fungerar.
"När du tittar på data, en samling av vad som helst, och du vill ta reda på en extremvärd – något som är annorlunda – du måste anta att alla databitar kommer från samma källa, samma fördelning. Ta en lista över offer efter födelseår. Det skulle ge en graf över åldern på varje person. Säg att 10 procent är äldre än 70 år. Nu, den distributionen skulle inte vara sant för en lista över deporterade barn, till exempel, eftersom den listan, per definition, är strukturellt annorlunda. Det skiljer sig också från en lista över alla som har ett identitetskort. Identitetskort utfärdas endast till personer som inte är barn. Än, listorna som dessa forskare arbetade med kom från en mängd källor och inkluderar listor över barn, listor över personer som gifter sig, listor över krigsfångar - saker som per definition inte kan ha kommit från samma distribution."
Ett annat stort fel i originaltidningen, Ornik sa, är att vissa dubbletter av listor behandlades som två separata listor. Detta innebar att cirka 67 procent av hela deras databas faktiskt var underlistor till den större listan.
"Den 7, 000-plus listor publicerade online av Förintelsemuseet är inte kurerade, " sa Ornik. "Till exempel, det finns två listor som innehåller exakt samma data; den ena är på kyrilliska och den andra använder det latinska alfabetet. Men de behandlade dem som två separata listor. Det finns andra listor som innehåller samma namn, men det finns inget sätt att veta om de är samma person eller två olika personer födda på samma dag med identiska namn. De kunde ha tagit bort de mycket allvarliga felen där en lista är tydligt duplicerad men resten, du skulle behöva tillgång till den ursprungliga historiska informationen."
Både originalpapperet och Orniks papper, "Kommentar till 'TVOR:Hitta diskreta totala variationsavvikelser bland histogram, '" publiceras i IEEE Access .