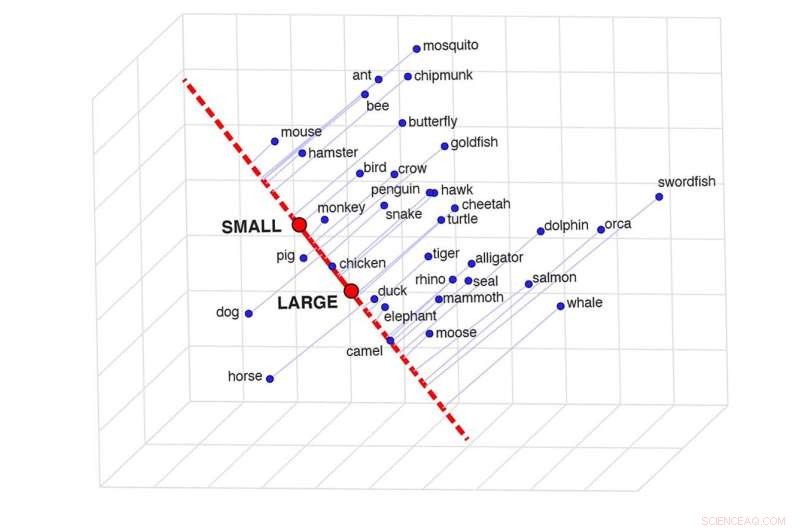
En skildring av semantisk projektion, som kan bestämma likheten mellan två ord i ett specifikt sammanhang. Detta rutnät visar hur lika vissa djur är baserat på deras storlek. Kredit:Idan Blank/UCLA
I "Through the Looking Glass" säger Humpty Dumpty hånfullt:"När jag använder ett ord betyder det precis vad jag väljer att det ska betyda - varken mer eller mindre." Alice svarar:"Frågan är om du kan få ord att betyda så många olika saker."
Studiet av vad ord verkligen betyder är åldrar gammalt. Det mänskliga sinnet måste analysera ett nät av detaljerad, flexibel information och använda sofistikerat sunt förnuft för att uppfatta deras mening.
Nu har ett nyare problem relaterat till ordens betydelse dykt upp:Forskare studerar om artificiell intelligens kan efterlikna det mänskliga sinnet för att förstå ord på det sätt som människor gör. En ny studie av forskare vid UCLA, MIT och National Institutes of Health tar upp den frågan.
Uppsatsen, publicerad i tidskriften Nature Human Behaviour , rapporterar att system med artificiell intelligens verkligen kan lära sig mycket komplicerade ordbetydelser, och forskarna upptäckte ett enkelt knep för att extrahera den komplexa kunskapen. De fann att AI-systemet de studerade representerar ordens betydelser på ett sätt som starkt korrelerar med mänskligt omdöme.
AI-systemet som författarna undersökte har använts ofta under det senaste decenniet för att studera ords betydelse. Den lär sig att räkna ut ords betydelser genom att "läsa" astronomiska mängder innehåll på internet, som omfattar tiotals miljarder ord.
När ord ofta förekommer tillsammans - "bord" och "stol", till exempel - lär sig systemet att deras betydelser är relaterade. Och om ordpar förekommer tillsammans mycket sällan – som "tabell" och "planet" – lär den sig att de har väldigt olika betydelser.
Det tillvägagångssättet verkar vara en logisk utgångspunkt, men tänk på hur väl människor skulle förstå världen om det enda sättet att förstå mening var att räkna hur ofta ord förekommer nära varandra, utan någon förmåga att interagera med andra människor och vår miljö.
Idan Blank, biträdande professor i psykologi och lingvistik vid UCLA, och studiens huvudförfattare, sa att forskarna satte sig för att lära sig vad systemet vet om orden det lär sig och vilken typ av "sunt förnuft" det har.
Innan forskningen började, sa Blank, verkade systemet ha en stor begränsning:"När det gäller systemet har vartannat ord bara ett numeriskt värde som representerar hur lika de är."
Däremot är mänsklig kunskap mycket mer detaljerad och komplex.
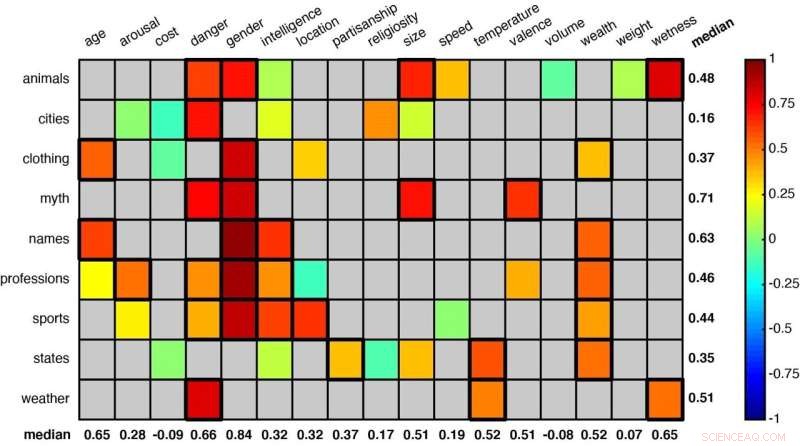
Ett rutnät som visar några av de ordkategorier som analyserats av forskarna. Statistiskt signifikanta parningar (som "djur" och "fara" och "djur" och "kön" på första raden) indikeras av rutor med en tjockare ram. Kredit:Idan Blank/UCLA
"Tänk på vår kunskap om delfiner och alligatorer," sa Blank. "När vi jämför de två på en storleksskala, från "liten" till "stor", är de relativt lika. När det gäller deras intelligens är de något olika. När det gäller den fara de utgör för oss, på en skala från "säkert" till "farligt", de skiljer sig mycket åt. Så ett ords betydelse beror på sammanhanget.
"Vi ville fråga om det här systemet faktiskt känner till dessa subtila skillnader - om dess idé om likhet är flexibel på samma sätt som det är för människor."
För att ta reda på det utvecklade författarna en teknik som de kallar "semantisk projektion". Man kan dra en gräns mellan modellens representationer av orden "stor" och "liten", till exempel, och se var representationerna av olika djur hamnar på den linjen.
Med den metoden studerade forskarna 52 ordgrupper för att se om systemet kunde lära sig att sortera betydelser – som att bedöma djur efter antingen deras storlek eller hur farliga de är för människor, eller klassificera amerikanska stater efter väder eller övergripande rikedom.
Bland de andra ordgrupperingarna fanns termer relaterade till kläder, yrken, sport, mytologiska varelser och förnamn. Varje kategori tilldelades flera sammanhang eller dimensioner – till exempel storlek, fara, intelligens, ålder och hastighet.
Forskarna fann att deras metod över dessa många föremål och sammanhang visade sig vara mycket lik mänsklig intuition. (För att göra den jämförelsen bad forskarna också kohorter på 25 personer vardera att göra liknande bedömningar om var och en av de 52 ordgrupperna.)
Anmärkningsvärt nog lärde sig systemet att uppfatta att namnen "Betty" och "George" liknar varandra när det gäller att vara relativt "gamla", men att de representerade olika kön. Och att "tyngdlyftning" och "fäktning" liknar varandra genom att båda vanligtvis äger rum inomhus, men olika vad gäller hur mycket intelligens de kräver.
"Det är en så vackert enkel metod och helt intuitiv," sa Blank. "Grensen mellan "stor" och "liten" är som en mental skala, och vi sätter djur på den skalan."
Blank sa att han faktiskt inte förväntade sig att tekniken skulle fungera men blev glad när den gjorde det.
"Det visar sig att detta maskininlärningssystem är mycket smartare än vi trodde; det innehåller mycket komplexa former av kunskap, och denna kunskap är organiserad i en mycket intuitiv struktur", sa han. "Bara genom att hålla reda på vilka ord som förekommer tillsammans med varandra i språket kan du lära dig mycket om världen."
Studiens medförfattare är MIT kognitiv neuroforskare Evelina Fedorenko, MIT doktorand Gabriel Grand och Francisco Pereira, som leder maskininlärningsteamet vid National Institutes of Healths National Institute of Mental Health.