Datorer är bra på att kategorisera bilder efter de föremål som hittas med dem, men de är förvånansvärt dåliga på att räkna ut när två objekt i en enda bild är lika eller olika varandra. Ny forskning hjälper till att visa varför den uppgiften är så svår för moderna datorseendealgoritmer. Kredit:Serre lab / Brown University
Algoritmer för datorseende har kommit långt under det senaste decenniet. De har visat sig vara lika bra eller bättre än människor på uppgifter som att kategorisera hund- eller kattraser, och de har den anmärkningsvärda förmågan att identifiera specifika ansikten ur ett hav av miljoner.
Men forskning från Brown University-forskare visar att datorer misslyckas med en klass av uppgifter som inte ens små barn har några problem med:att avgöra om två objekt i en bild är lika eller olika. I en artikel som presenterades förra veckan vid det årliga mötet i Cognitive Science Society, Brown-teamet belyser varför datorer är så dåliga på dessa typer av uppgifter och föreslår vägar mot smartare datorseendesystem.
"Det finns mycket spänning över vad datorseende har kunnat åstadkomma, och jag delar mycket av det, sa Thomas Serre, docent i kognitiv, lingvistiska och psykologiska vetenskaper vid Brown och tidningens seniorförfattare. "Men vi tror att genom att arbeta för att förstå begränsningarna hos nuvarande datorseendesystem som vi har gjort här, vi kan verkligen gå mot nya, mycket mer avancerade system snarare än att bara justera de system vi redan har."
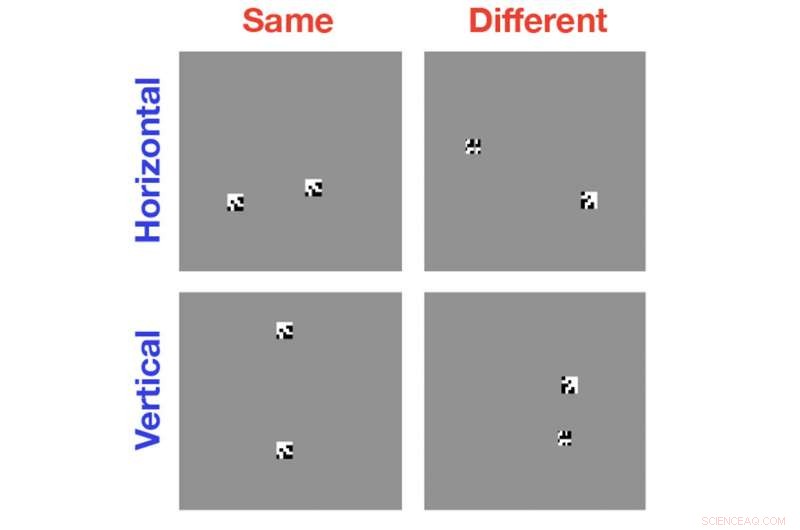
För studien, Serre och hans kollegor använde toppmoderna datorseendealgoritmer för att analysera enkla svartvita bilder som innehåller två eller flera slumpmässigt genererade former. I vissa fall var föremålen identiska; ibland var de samma men med ett föremål roterat i förhållande till det andra; ibland var föremålen helt olika. Datorn ombads identifiera samma-eller-olika relation.
Studien visade att, även efter hundratusentals träningsexempel, Algoritmerna var inte bättre än chansen att känna igen det lämpliga förhållandet. Frågan, sedan, var varför dessa system är så dåliga på denna uppgift.
Serre och hans kollegor hade en misstanke om att det har något att göra med dessa datorseendealgoritmers oförmåga att individualisera objekt. När datorer tittar på en bild, de kan faktiskt inte se var ett objekt i bilden stannar och bakgrunden, eller annat föremål, börjar. De ser bara en samling pixlar som har liknande mönster som samlingar av pixlar som de har lärt sig att associera med vissa etiketter. Det fungerar bra för identifierings- eller kategoriseringsproblem, men faller isär när man försöker jämföra två objekt.
För att visa att det verkligen var därför algoritmerna gick sönder, Serre och hans team utförde experiment som befriade datorn från att behöva individualisera objekt på egen hand. Istället för att visa datorn två objekt i samma bild, forskarna visade på datorn objekten ett i taget i separata bilder. Experimenten visade att algoritmerna inte hade några problem att lära sig samma-eller-olika relationer så länge de inte behövde se de två objekten i samma bild.
Källan till problemet med att individualisera objekt, Serre säger, är arkitekturen för maskininlärningssystem som driver algoritmerna. Algoritmerna använder konvolutionella neurala nätverk - lager av anslutna bearbetningsenheter som löst efterliknar nätverk av neuroner i hjärnan. En nyckelskillnad från hjärnan är att de artificiella nätverken uteslutande är "feed-forward" - vilket innebär att information har ett enkelriktat flöde genom nätverkets lager. Det är inte så det visuella systemet hos människor fungerar, enligt Serre.
"Om du tittar på anatomin i vårt eget synsystem, du upptäcker att det finns många återkommande kopplingar, där informationen går från ett högre synområde till ett lägre synområde och tillbaka genom, sa Serre.
Även om det inte är klart exakt vad dessa återkopplingar gör, Serre säger, det är troligt att de har något att göra med vår förmåga att uppmärksamma vissa delar av vårt synfält och göra mentala representationer av objekt i våra sinnen.
"Förmodligen tar folk hand om ett föremål, bygga en egenskapsrepresentation som är bunden till det objektet i deras arbetsminne, "Sade Serre. "Då flyttar de sin uppmärksamhet till ett annat föremål. När båda objekten är representerade i arbetsminnet, ditt visuella system kan göra jämförelser som samma-eller-olika."
Serre och hans kollegor antar att anledningen till att datorer inte kan göra något sådant är att neurala nätverk med feed-forward inte tillåter den typ av återkommande bearbetning som krävs för denna individualisering och mentala representation av objekt. Det kan vara, Serre säger, att göra datorseende smartare kommer att kräva neurala nätverk som närmare liknar den återkommande karaktären hos mänsklig visuell bearbetning.